
 It’s hard not to be fascinated by machine learning. They’re overwhelmingly powerful. Even Steve Ballmer says machine learning will be the next era of computer science. There is lot of buzz around machine learning now a days. So I thought of discussing some simple machine learning concepts to motivate you .
It’s hard not to be fascinated by machine learning. They’re overwhelmingly powerful. Even Steve Ballmer says machine learning will be the next era of computer science. There is lot of buzz around machine learning now a days. So I thought of discussing some simple machine learning concepts to motivate you .
so lets get started,
1) Ensemble Methods
Ensemble methods are really cool to know . A single decision tree does not perform well. But, it is super fast.
Ensemble methods are learning algorithms that construct a set of classifiers and then classify new data points by taking a (weighted) vote of their predictions. In this post, I will be talking about some of the popular ensemble methods such as bagging, boosting and random forests.
If I were to define ensembles in one line, then I would define them as follows:
Aggregation of predictions of multiple classifiers with the goal of improving accuracy.
But If you want to train multiple classifiers you need more data. The more degrees of freedom your model has the more data your model tries to fit and more data points you want to have, this is where boot strapping comes to help you.
2) Boot Strapping
You use the data you have and try to make it more, this is what boot strapping does. Take N data points and draw N times with replacement, this means you end up with multiple sets of same size. As you sample with replacement, all of these samples are slightly different. You can use each of these data sets as one data set on its own.
Remember, you cannot do cross validation on this because if you have bootstrap samples x1 and x2 there are going to be points that are both in x1 and x2.
For Further understanding of boot strapping read this thread on stack exchange.
3) Bagging
First ensemble method that we are going to talk about is Bagging. One of the disadvantage in decision trees is they will look different if there are slight variations in the data, ensembles converts this disadvantage into an advantage.
Bagging follows these steps:
1) Sample with replacement from your data set(boot strapping)
2) Learn a classifier for each bootstrap sample
3) Average the results of each classifier
when each boot strap sample looks slightly different then you get different decision trees. You can average them and you can get a nice boundary. Bagging reduces over fitting significantly.
The basic idea of Bagging is to average noisy and unbiased models to create a model with low variance in terms of classification. Watch this video on bagging to understand more about it.
4) Random Forest
Random forests uses lot of decision trees to create a classification. The parameters are number of features and number of trees. Random forest is called off the shelf classifier, most of the time you need not even bother about these parameters.
If you have understood the concept of decision trees then understanding random forest is really easy. I would recommend you to read Edwin chen’s Layman introduction torandom forest and also watch Thales video on random forest.
Random forest error rate depends on: correlation between the trees and strength of single trees.
But if you increase the number of features for each split, then it increases the correlation between the trees and increases the strength of single trees. If your trees are not that different then your averaging doesn’t give you as much as improvement as you want. Single trees should be really strong, you want each tree in there to actually learn something. So there is a trade off here.
a) Out Of Bag Error:
Out of bag error is the in built version for computing the test error. It is very nice because you dont have to put the data set aside in the beginning. You take the boot strap sample, and the boot strap sample covers 60 % of the original data points and you have 30 % that you didn’t use. The idea is you can use these 30 % as points to estimate the test error. If I make boot strap samples and I end up with 500 of those, that is for each single tree(not for the whole forest), I have my boot strap sample and I have the rest left over training points that didnt make into my boot strap sample. Those I can use to estimate the test performance for that single tree, again not for the whole forest, just for the single tree. The Idea is you can do that for each single tree and that can give you the overall performance of random forest, because you know how strong the single trees are. Still I will not count the out of bag error as test error. If you plot them one against the another, most of the time you will get a positive, because it is not the true test error.
You can use out of bag error for validation, you can tune the number of trees. You can read Leo Breiman out of bag estimation article to know more about out of bag error.
b) Variable Importance:
Random forests allow you to compute a heuristic for determining how “important” a feature is in predicting a target. This heuristic measures the change in prediction accuracy if you take a given feature and permute (scramble) it across the datapoints in the training set. The more the accuracy drops when the feature is permuted, the more “important” we can conclude the feature is.
eg: Suppose you have 1000 men and 1000 women, measure everyone’s height and model height as predicted by sex. In your random forest context, you can assess predictive accuracy out-of-bag.
Now, if sex were irrelevant to height, then you should get (roughly) the same predictive accuracy if you randomly shuffled everyone’s M/F identification.
That is exactly what RF variable importance does: shuffle each observation’s value on one variable, reassess predictive accuracy and compare to accuracy on the unshuffled data. If the shuffled data predict as well as unshuffled data, the variable is obviously not very important for prediction. If the shuffled data predict worse, then the variable is important.
5) UnBalanced Classes
Unbalanced classes means you have 8000 class A points and 2000 class b points, your job is to make the classifier understand how important the class B points are. One version to handle unbalanced classes is over sample( keep on sampling till you have 2 data sets that are of same size). Other option is to down sample the majority class. Random forest gives a nice solution for this that is you can sub sample for each tree. So that each of the trees are balanced now, in the end the algorithm has seen everything from the majority class.

6) Precision and Recall
Precision or recall is a evaluation metric for classification problem with skewed classes. For many application you have to control the tradeoff between precision and recall. Consider cancer prediction example; if you modify your hypothesis (h(x)) to 0.7 to predict cancer confidently, then you end up with a classifier that will have high precision and low recall. In this case, if a patient has cancer, but you fail to tell them they do not have one. If you set (h(x)) to 0.3, then you have high recall and low precision. Here, your classifier may predict most of them as having cancer. For most of the classifiers there is going to be a tradeoff between precision and recall.
Is there a way to chose threshold automatically? How do you decide which of these threshold are the best? This is where f score comes in. F score is the harmonic mean of precision and recall.
To understand more about precision and recall, please watch professor Andrew Ngs week 6 system design videos
7) Boosting
It is kind of an ensemble method but it does something more than averaging. You train one classifier, you look at the results and you make correction, and you train two, you look at the results and you make corrections, and you average them with weights. One that performed really well I want to put high weight on that classifier, but if the other one did not perform really well so it actually gets less weight.
Boosting is better than bagging for many applications. Read more about boosting here.
a) Ada Boost
In Ada boost, you draw one decision boundary and look at the classification performance, few of the points are going to be mistakes. I am going to put lot of weights on these points( that are misclassified, line 1) and I am going to say to these points that for the next classifier that I am going to train please pay attention and get those points right. whats gonna happen is I am going to get a different decision boundary the next time(line 2). Instead of introducing this randomness thing I am looking at the performance of the previous classifier and try to correct the mistakes it made.
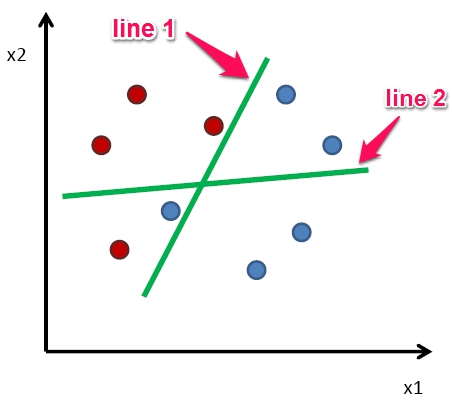
Most of the time ada boost works with decision stumps even. decision stumps are only a tree that does only one split this means one x’s align split on one feature thats all your whole classifier. In really life the figure ada boost the line wont be diagonal it will be a xs aligned split.
Conclusion
So far I have discussed about some of the most important concepts in machine learning. I would like to depict the concept of ensemble with this quote:
The collective knowledge of a diverse and independent body of people typically exceeds the knowledge of any single individual, and can be harnessed by voting- James Surowiecki
Ensembles were the method of choice to win Netflix prize, you can watch the video here.
About Author:
Manu Jeevan writes about digital analytics, data science and growth hacking. His love for data science and analytics started when he was doing his MBA. To sharpen his digital analytics and data analysis skills, he took special interest in subjects like business analytics, market research and statistics. Currently he spends all of his time on Big-data-examiner.com, his number one goal is to share what he had learned with others.






























